RubyでTwitterの仲間探し
皆さんのTLは賑わっているでしょうか? TLをより活気づけるためには誰かをフォローするのが一番ですが,はてさて誰をフォローしたものか……と悩まれたことはないでしょうか?
Twitterはこうしたユーザーをサポートするために「おすすめユーザー」を表示する機能を提供していますが,どういうアルゴリズムでおすすめユーザーを選んでいるのか不明な上,少なくとも私にはあまり精度(実際にフォローしようと思えるアカウントの割合)が高いようにも思われません.
そこで,「自分のフォローしているユーザー(フォロイー)からたくさんフォローされているユーザー」ならば「自分のフォローしたいユーザー」である確率が高いと考え,そのランキングを出力するRubyスクリプトを書きました.
仕様を考える
「フォロイーのフォロイー」ランキングを作成する,という目的は極めて単純明快なのですが,Twitterが我々に課している厳しいAPI制限が厄介です.
特に,指定ユーザーのフォロイー一覧を取得するAPI(friends/ids)は15分間に15回までしか使えません.私のアカウントのフォロイーは現在約150人ですが,もし1アカウントでこの解析を行うとすると,雑に計算しても2時間半以上の時間を要します.そんなに待つのは嫌なので,調査対象のアカウント(以下,ターゲット)以外にも任意個の補助アカウントを協働させられるようにしました.複数アカウント体制でもすべてのアカウントがAPI規制を受けている最中はどうしようもないので,待機してAPI規制が解除されたものから順次再稼働させます.
また,複数アカウント体制特有の問題として非公開アカウント(通称,鍵垢)の存在があります.鍵垢のフォロイーは当該鍵垢のフォロワーでないと取得できないため,補助アカウントでは基本的にこれを扱うことができません.そこで,ターゲットアカウントでは鍵垢を優先的に処理するように工夫する必要があります.
ここまでに記した要求をざっとまとめると次のようになります.
- ターゲットの「フォロイーのフォロイー」ランキングを作成する
- データの取得は複数のアカウントで実施できるようにする
- 全アカウントが規制されているときは,最初のアカウントが規制解除されるまで待機する
- ターゲットアカウントには鍵垢を優先的に処理させる(補助アカウントでは処理できない)
なお,Twitter APIを直接叩くのは面倒なのでTwitter Gemを利用しました.また,出力は諸事情(後述)によりHTML形式で行わせます.
以上が,今回作成したスクリプトの仕様概略です.より細かな仕様は,次節で実装とともに紹介します.
実装する
OAuth認証
Twitter APIを利用するための前提条件として,いくつかのキーを取得する必要があります.
Consumer
Twitter Developersでアプリケーションを登録し,〈Consumer Key〉と〈Consumer Secret〉を取得します(やり方がわからなければこの記事でも参照してください).得られた文字列を,以下の定数に代入しておきます.
# アプリケーションの設定 CONSUMER_KEY = "〈Consumer Key〉" CONSUMER_SECRET = "〈Consumer Secret〉"
Access Token
アカウント1つ分であれば,これもTwitter Developersで取得できるのですが,今回は複数のアカウントを使用するので別の手を使う必要があります.どのように入手して頂いても構いませんが,私はこのスクリプトを利用しました.
ターゲットのアクセストークンは以下の定数に代入します.
# ターゲットの設定 TARGET_ACCESS_TOKEN = "〈Target's Access Token〉" TARGET_ACCESS_TOKEN_SECRET = "〈Target's Access Token Secret〉"
一方,補助アカウントについては〈Access Token〉と〈Access Token Secret〉を組にした配列を必要な個数だけ用意し,それを最終的に1つの2次元配列にまとめた形で与えます.
# 補助アカウントの設定 RESEARCH_ACOUNTS_TOKENS = [ ["〈Access Token 1〉", "〈Access Token Secret 1〉"], ["〈Access Token 2〉", "〈Access Token Secret 2〉"], ["〈Access Token 3〉", "〈Access Token Secret 3〉"], ["〈Access Token 4〉", "〈Access Token Secret 4〉"] ]
ResearchAccountクラス
各調査用アカウント(ターゲットアカウントと補助アカウント)を管理するためのクラスを作成します.ここでは,定義したメソッド毎に分割して掲載しておきます.
インスタンスの生成
インスタンス生成時には"〈Access Token〉"と"〈Access Token Secret〉"を引数に与え,これらから生成されるTwitter::REST::Clientクラスのインスタンスを,インスタンス変数@clientに代入します.
また,このクライアントが規制を受けた際に規制終了時間を格納しておくためのインスタンス変数@limit_end_pointも初期値をnilとして用意しておきます.さらに,@limit_end_pointは外部からも読み出したいのでattr_readerを宣言してあります.
そして,target変数にResearchAccountのインスタンス(ターゲット)を1つ,research_accountsにResearchAccountのインスタンス(補助アカウント)を必要な数だけ格納した配列を代入します.
class ResearchAccount attr_reader :limit_end_point def initialize(token, token_secret) @client = Twitter::REST::Client.new do |config| # アカウントを設定 config.consumer_key = CONSUMER_KEY config.consumer_secret = CONSUMER_SECRET config.access_token = token config.access_token_secret = token_secret end @limit_end_point = nil # 規制終了時間 end end target = ResearchAccount.new(TARGET_ACCESS_TOKEN, TARGET_ACCESS_TOKEN_SECRET) research_accounts = RESEARCH_ACOUNTS_TOKENS.map{ |t| ResearchAccount.new(t[0], t[1]) }
friend_idsメソッド
Twitterのfriends/ids APIを叩いて,指定ユーザー(本スクリプトではTwitter ID.以下も同様)の全フォロイーのID *1 を格納した配列を取得します.引数を省略した場合は,自身のフォロイーのID一覧が取得されます.
class ResearchAccount def friend_ids(id = "") # フォロイーを取得 @client.friend_ids(id).attrs[:ids] end end
secret_account?メソッド
指定ユーザーが鍵垢かどうかを判定します(鍵垢のときtrueを返す).引数は省略できません.
鍵垢の判定には「(権限がないのに)鍵垢の詳細情報を取得しようとするとTwitter::Error::Unauthorizedエラーが発生する」ことを利用しています.この「取得する詳細情報」ですが,friends/ids APIを叩いてしまうと,それだけで残存API回数を消費してしまうので,15分間で180回まで使用可能なstatuses/user_timeline APIを叩いてエラーの有無を見るようにしています.
class ResearchAccount def secret_account?(id) # 鍵垢を判定 @client.user_timeline(id) rescue Twitter::Error::Unauthorized true else false end end
friend_ids_limited?メソッド
名前の通り,friends/ids APIが規制されているかどうかを判定する(規制中のときtrueを返す)メソッドですが,もう1つ重要な機能を持たせてあります.
このメソッドを呼び出すと,自身の@limit_end_pointが現状に則した値に更新されます.すなわち,friends/ids APIが規制中の場合は規制解除時間(UNIX時間)を表す整数が,そうでない場合はnilが代入された状態になります.
なお,規制有無の判定は15分間に180回使用可能なapplication/rate_limit_status APIを叩いた結果により行なわれます.
class ResearchAccount def friend_ids_limited? # friends/ids API の規制を判定 if @limit_end_point != nil return true if Time.now.to_i < @limit_end_point end limited_data = @client.__send__(:perform_get, '/1.1/application/rate_limit_status.json') if limited_data[:resources][:friends][:"/friends/ids"][:remaining] == 0 @limit_end_point = limited_data[:resources][:friends][:"/friends/ids"][:reset] true else @limit_end_point = nil false end end end
ターゲットのフォロイーを取得
ResearchAccountクラスで定義されたメソッドを用いてターゲットの全フォロイーのIDを格納した配列を取得します.
ただし,実際にfriends/ids APIを叩く前に規制されていないかどうかのチェックが入ります.もし,規制中であった場合は待つ以外に方法がなく,また保持しておくべきデータも存在しないので「ターゲットのAPIが規制中です.しばらくしてから再度お試しください.」というメッセージをコンソールに出して終了します.
APIが規制中でない場合は,ResearchAccount#friend_idsメソッドで目的の配列を取得し,untreated_followees変数に代入します.また,この配列のサイズ(すなわちターゲットのフォロイー数)を定数TARGET_FOLLOWEESに格納しておきます.
if target.friend_ids_limited? puts "ターゲットのAPIが規制中です.しばらくしてから再度お試しください." exit end untreated_followees = target.friend_ids # 未処理のフォロイーのID配列 TARGET_FOLLOWEES = untreated_followees.size # ターゲットのフォロイー数 puts "ターゲットのフォロイーを取得完了."
調査の実行
ここまで色々と用意をしてきましたが,いよいよ実際の調査実行部分です.
複数アカウントで調査しても混乱が生じないよう,調査対象のフォロイーIDを進行状況に応じた配列に移動させていくことで重複等が発生しないようにします.
ということで,まずそのための配列を用意します(未処理のフォロイーIDを格納するuntreated_followeesは前小節掲載の箇所で作成済みである点にご注意ください).それぞれの用途はソースのコメントにある通りです.
treated_followees = [] # 処理済みのフォロイーのID配列 secret_followees = [] # 鍵垢のフォロイーのID配列 followees_followees = [] # フォロイーのフォロイーのID配列
あとは,エラーが発生しないように慎重に条件を絞りながら調査を実行するだけです.ただし,ループが二重になっている箇所がある上,調査が終了しているにも関わらずループ中で規制解除待ちに入ってしまうような事態を極力避けたいということで大域脱出を用いているため,見た目が少々複雑です.
puts "データを取得中..." catch :main_loop do loop do limit_end_point = [] # 最初の規制解除までの時間 research_accounts.each do |account| # 補助アカウントによる調査 until account.friend_ids_limited? || untreated_followees.empty? followee = untreated_followees.shift if account.secret_account?(followee) secret_followees << followee else followees_followees += account.friend_ids(followee) treated_followees << followee end str = "-----#{treated_followees.size}/#{TARGET_FOLLOWEES}-----" printf str printf "\e[#{str.size}D" STDOUT.flush throw :main_loop if treated_followees.size == TARGET_FOLLOWEES end limit_end_point << account.limit_end_point unless untreated_followees.empty? end until target.friend_ids_limited? # ターゲットによる調査 if secret_followees.empty? followee = untreated_followees.shift else followee = secret_followees.shift end followees_followees += target.friend_ids(followee) treated_followees << followee str = "-----#{treated_followees.size}/#{TARGET_FOLLOWEES}-----" printf str printf "\e[#{str.size}D" STDOUT.flush throw :main_loop if treated_followees.size == TARGET_FOLLOWEES end limit_end_point << target.limit_end_point if limit_end_point.all? # 全アカウントが規制中の場合 sleep_time = limit_end_point.min - Time.now.to_i if sleep_time > 0 puts "-----#{treated_followees.size}/#{TARGET_FOLLOWEES}-----" puts "API制限のため待機中..." sleep sleep_time puts "データを取得中..." end end end end
しかし,実際はそれほど複雑な操作ではありません.簡単にまとめると次のようになります.
- すべての補助アカウントがAPIを使い切る(もしくは非鍵垢の調査が終了する)までは補助アカウントによって調査を行う.その際,鍵垢と判定されたIDはすべて配列
secret_followeesに格納しておく. - ターゲットは
secret_followeesに格納されたIDについて調査を行う.secret_followeesが空になった場合に限り,untreated_followeesのIDを処理する. - ターゲットのAPIが規制された時点で,APIが使用可能なアカウントが1つでもあれば再び1に戻る.すべて使用不能の場合は,最初に規制が解除されるアカウントの規制解除時間まで待機したのち1に戻る.
treated_followeesのサイズがターゲットのフォロイー数(TARGET_FOLLOWEES)と一致した時点で上記ループを抜ける.
これで,すべてのフォロイーのすべてのフォロイー(のID)がfollowees_followeesにそのまま(重複を許して)格納されました.
ランキングの作成
取得したデータfollowees_followeesの重複を集計し,降順に並べます.
その前の準備として,Arrayクラスにcountメソッドを定義しておきます.これをfollowees_followeesに作用させると,〈ID〉 => 〈個数〉を集めたハッシュが返ります
*2
.
class Array def count # 要素の重複数を数える(戻り値:Hash) k = Hash.new(0) self.each{|x| k[x] += 1 } return k end end puts "-----#{treated_followees.size}/#{TARGET_FOLLOWEES}-----" puts "データを分析中..." result = followees_followees.count # 重複をカウント(出力はハッシュ)
次に,集計結果の中から既にターゲットがフォローしているユーザーを除去します.EXCEPT_MY_FOLLOWEEにfalseを代入することで,除去しないことも可能です.
さらに,MAX_RANKで指定したユーザー数以下になるまで下位のユーザーから順に除去していきます.MAX_RANKで指定するのは最大値なので,100ユーザー目と101ユーザー目が同じ順位のときは100ユーザー目もランキングから除去されます.
以上で,最終的に出力するユーザーIDが確定するので,最後にこれを昇順にソートしてデータ整理は終了します.
if EXCEPT_MY_FOLLOWEE # true ならターゲットの関係者を除去 treated_followees.each do |f| result.delete(f) end end i = 1 while result.size > MAX_RANK # 要素数を MAX_RANK 以内に result.reject!{ |key, val| val == i } i += 1 end result = result.sort_by{ |key, val| val }.reverse # 値でソート(配列で戻る)
HTMLを出力
これまでも述べてきたように,本スクリプトではユーザーを識別するデータにTwitter IDを使用しています.人間が読むためには,当然スクリーン名で表示する方が良いのですが,Twitter IDからスクリーン名を得るためには再びTwitter APIを叩く必要が生じ,場合によっては最後にさらに規制時間の終了を待たねばならなくなります.
こうした事態を避けるため,スクリーン名を取得せずに,Twitter IDから当該ユーザーのプロフィールページにリンクを張るようなHTMLで出力することにしました.
出力するHTMLのファイル名ですが,本スクリプトは実行に時間がかかるため,データを損失すると打撃が大きいということで,既存のファイルを上書きしてしまわないように工夫してあります.
ranking_list = "" result.each do |a| ranking_list += '<li><a href="https://twitter.com/intent/user?user_id=' + a[0].to_s + '.html">' + a[0].to_s + "</a> (" + a[1].to_s + ")</li>\n" end ranking_html = <<"HTML" <!DOCTYPE html><html> <head> <meta charset="utf-8"> <title>Ranking</title> </head> <body> <h1>Followee's Followee Rancking</h1> <ol> #{ranking_list} </ol> </body> </html> HTML unless File.exist?('ranking.html') # ファイル名の初期値:ranking.html File.open 'ranking.html', 'w' do |html| html.write(ranking_html) end puts "結果を ranking.html に出力しました." else # 既存のファイルは上書きしない i = 1 i += 1 while File.exist?("ranking-#{i}.html") File.open "ranking-#{i}.html", 'w' do |html| html.write(ranking_html) end puts "結果を ranking-#{i}.html に出力しました." end
まとめ
ここまでのコードをまとめると,次のようなスクリプトが完成します.
require 'twitter' # ランキングの設定 MAX_RANK = 100 EXCEPT_MY_FOLLOWEE = true # アプリケーションの設定 CONSUMER_KEY = "〈Consumer Key〉" CONSUMER_SECRET = "〈Consumer Secret〉" # ターゲットの設定 TARGET_ACCESS_TOKEN = "〈Target's Access Token〉" TARGET_ACCESS_TOKEN_SECRET = "〈Target's Access Token Secret〉" # 補助アカウントの設定 RESEARCH_ACOUNTS_TOKENS = [ ["〈Access Token 1〉", "〈Access Token Secret 1〉"], ["〈Access Token 2〉", "〈Access Token Secret 2〉"], ["〈Access Token 3〉", "〈Access Token Secret 3〉"], ["〈Access Token 4〉", "〈Access Token Secret 4〉"] ] # 調査用アカウントを管理するクラス class ResearchAccount attr_reader :limit_end_point def initialize(token, token_secret) @client = Twitter::REST::Client.new do |config| # アカウントを設定 config.consumer_key = CONSUMER_KEY config.consumer_secret = CONSUMER_SECRET config.access_token = token config.access_token_secret = token_secret end @limit_end_point = nil # 規制終了時間 end def friend_ids(id = "") # フォロイーを取得 @client.friend_ids(id).attrs[:ids] end def secret_account?(id) # 鍵垢を判定 @client.user_timeline(id) rescue Twitter::Error::Unauthorized true else false end def friend_ids_limited? # friends/ids API の規制を判定 if @limit_end_point != nil return true if Time.now.to_i < @limit_end_point end limited_data = @client.__send__(:perform_get, '/1.1/application/rate_limit_status.json') if limited_data[:resources][:friends][:"/friends/ids"][:remaining] == 0 @limit_end_point = limited_data[:resources][:friends][:"/friends/ids"][:reset] true else @limit_end_point = nil false end end end # 調査用アカウント・インスタンスの生成 target = ResearchAccount.new(TARGET_ACCESS_TOKEN, TARGET_ACCESS_TOKEN_SECRET) research_accounts = RESEARCH_ACOUNTS_TOKENS.map{ |t| ResearchAccount.new(t[0], t[1]) } # Arrayクラスにcountメソッドを定義 class Array def count # 要素の重複数を数える(戻り値:Hash) k = Hash.new(0) self.each{|x| k[x] += 1 } return k end end # ターゲットのフォロイーを取得 if target.friend_ids_limited? puts "ターゲットのAPIが規制中です.しばらくしてから再度お試しください." exit end untreated_followees = target.friend_ids # 未処理のフォロイーのID配列 TARGET_FOLLOWEES = untreated_followees.size # ターゲットのフォロイー数 puts "ターゲットのフォロイーを取得完了." # 配列の用意 treated_followees = [] # 処理済みのフォロイーのID配列 secret_followees = [] # 鍵垢のフォロイーのID配列 followees_followees = [] # フォロイーのフォロイーのID配列 # 調査の実行 puts "データを取得中..." catch :main_loop do loop do limit_end_point = [] # 最初の規制解除までの時間 research_accounts.each do |account| until account.friend_ids_limited? || untreated_followees.empty? followee = untreated_followees.shift if account.secret_account?(followee) secret_followees << followee else followees_followees += account.friend_ids(followee) treated_followees << followee end str = "-----#{treated_followees.size}/#{TARGET_FOLLOWEES}-----" printf str printf "\e[#{str.size}D" STDOUT.flush throw :main_loop if treated_followees.size == TARGET_FOLLOWEES end limit_end_point << account.limit_end_point unless untreated_followees.empty? end until target.friend_ids_limited? if secret_followees.empty? followee = untreated_followees.shift else followee = secret_followees.shift end followees_followees += target.friend_ids(followee) treated_followees << followee str = "-----#{treated_followees.size}/#{TARGET_FOLLOWEES}-----" printf str printf "\e[#{str.size}D" STDOUT.flush throw :main_loop if treated_followees.size == TARGET_FOLLOWEES end limit_end_point << target.limit_end_point if limit_end_point.all? # 全アカウントが規制中の場合 sleep_time = limit_end_point.min - Time.now.to_i if sleep_time > 0 puts "-----#{treated_followees.size}/#{TARGET_FOLLOWEES}-----" puts "API制限のため待機中..." sleep sleep_time puts "データを取得中..." end end end end # 結果の分析 puts "-----#{treated_followees.size}/#{TARGET_FOLLOWEES}-----" puts "データを分析中..." result = followees_followees.count # 重複をカウント(出力はハッシュ) if EXCEPT_MY_FOLLOWEE # true ならターゲットの関係者を除去 treated_followees.each do |f| result.delete(f) end end i = 1 while result.size > MAX_RANK # 要素数を MAX_RANK 以内に result.reject!{ |key, val| val == i } i += 1 end result = result.sort_by{ |key, val| val }.reverse # 値でソート(配列で戻る) # HTML形式で出力 ranking_list = "" result.each do |a| ranking_list += '<li><a href="https://twitter.com/intent/user?user_id=' + a[0].to_s + '.html">' + a[0].to_s + "</a> (" + a[1].to_s + ")</li>\n" end ranking_html = <<"HTML" <!DOCTYPE html><html> <head> <meta charset="utf-8"> <title>Ranking</title> </head> <body> <h1>Followee's Followee Rancking</h1> <ol> #{ranking_list} </ol> </body> </html> HTML unless File.exist?('ranking.html') # ファイル名の初期値:ranking.html File.open 'ranking.html', 'w' do |html| html.write(ranking_html) end puts "結果を ranking.html に出力しました." else # 既存のファイルは上書きしない i = 1 i += 1 while File.exist?("ranking-#{i}.html") File.open "ranking-#{i}.html", 'w' do |html| html.write(ranking_html) end puts "結果を ranking-#{i}.html に出力しました." end
使ってみる
では,完成したスクリプトを実際に使用しています.私のメインアカウント(@Watson_DNA)をターゲットとして,4つの補助アカウントを加えた計5アカウント体制で解析してみました.
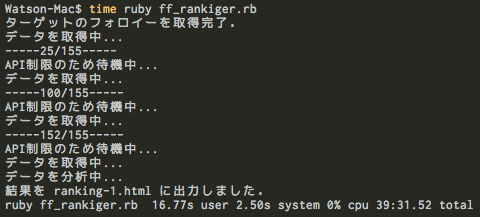
ターゲットのフォロイーは150程度ですが,timeコマンドで実行時間を計測したところ,上記の通り約40分ほどかかりました.大方の予想通り,かかった時間のほとんどはAPI規制解除までの待機時間です.
さて,気になる第1位,すなわち私が最もフォローすべきアカウントは……こちらです!
第1位:507259667 (147)
あれ……これって自分じゃないですか!
はい,フォロイーを除去した時点で安心して自分自身を除去するのをすっかり忘れていました.まぁ,1アカウントだけなのでこのぐらいは目を瞑ることにします.
出力データはとりあえずここにおいておきました.
感想
TwitterのAPI制限はつらい.これに尽きます.